LOS J requires us to:
identify the appropriate test statistic and interpret the results for a hypothesis test concerning 1) the variance of a normally distributed population, and 2) the equality of the variances of two normally distributed populations based on two independent random samples
There are two types of tests for variances, i.e. tests concerning the value of single population variance and tests concerning the differences between two population variances.
1. Testing a Single Variance
a. The hypothesis for testing the variance is:
i.
(a “not equal to” alternative hypothesis)
ii. 
(a “greater than” alternative hypothesis)
iii. 
(a “less than” alternative hypothesis)
b. The test for single variance is done using chi-square test statistics, which is denoted by χ2.
c. As the value of the variance cannot be negative (since it has a square figure in the numerator and a positive number in the denominator), the value of the test statistic of chi-square is also greater than zero.
Thus we can say that the distribution of chi-square is bounded by zero in the left tail and has an extended right tail.
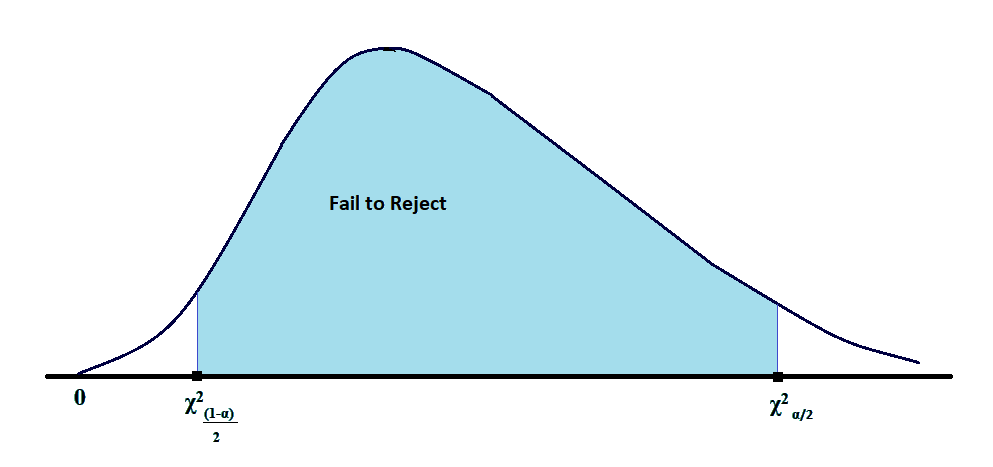
In the above figure, if the test was one-tailed, instead of two-tailed, it would have been α or (1-α) instead of α/2 or (1-α)/2
d. The test statistic for the chi-square test is:
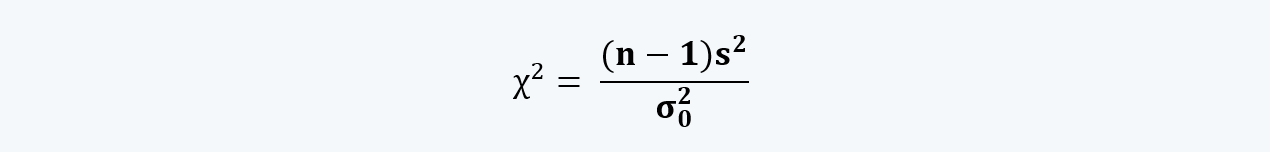
e. The chi-square test for single variance is done with a degree of freedom of n-1 and is very sensitive to the underlying assumptions.
2. Tests Comparing Two Variance Measures
a. Tests for comparing two variances are conducted if we have two normally distributed populations with means μ1and μ2 and variances σ12 and σ22.
b. The hypothesis for this test is written as follows:

c. Note that, in the hypothesis, H0: σ12 = σ22, we have H0: σ12 / σ22 =1.
d. Therefore the test statistic for the test of two variances (i.e. f-test statistic) is:
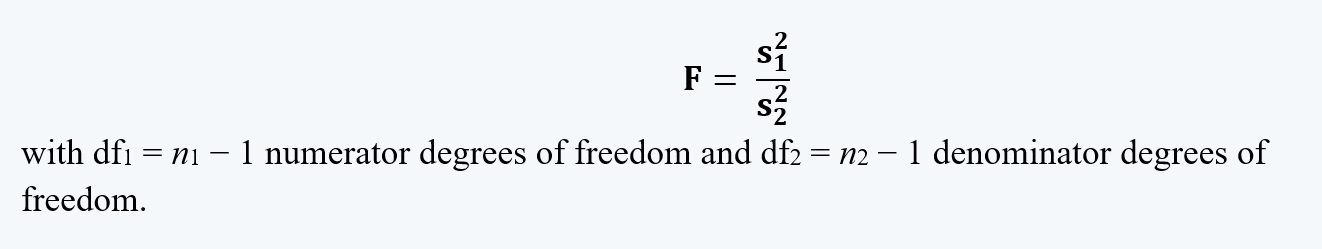
e. Since the f-statistic is the ratio between the two variances, and this ratio does affect the curvature of the distribution. Now, the question is which sample’s variance should be chosen as the numerator for the calculations?
The answer is that we should choose the sample with a larger variance as the numerator.
f. Finally, we make the decision as follows:
‘if the test statistic is greater than the critical value for an F-distribution with df1 and df2 degrees of freedom, reject the null hypothesis’.