LOS A, B, and C requires us to:
a. define simple random sampling and a sampling distribution
b. explain sampling error
c. distinguish between simple random and stratified random sampling
Before, we understand the methodology and technique of sampling; it is important to understand its concepts. These concepts include parameters, statistics, and samples.
1. Parameters & Statistics
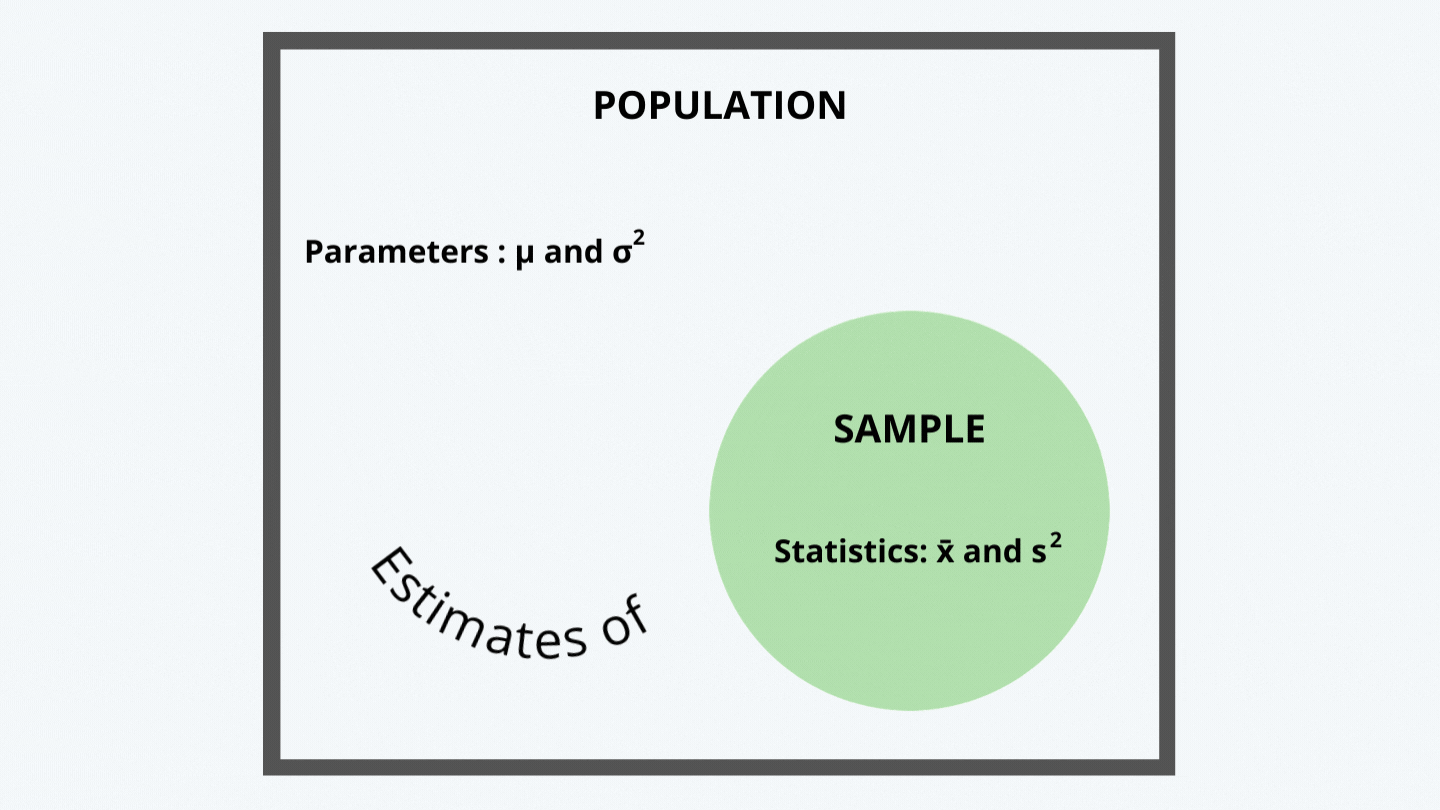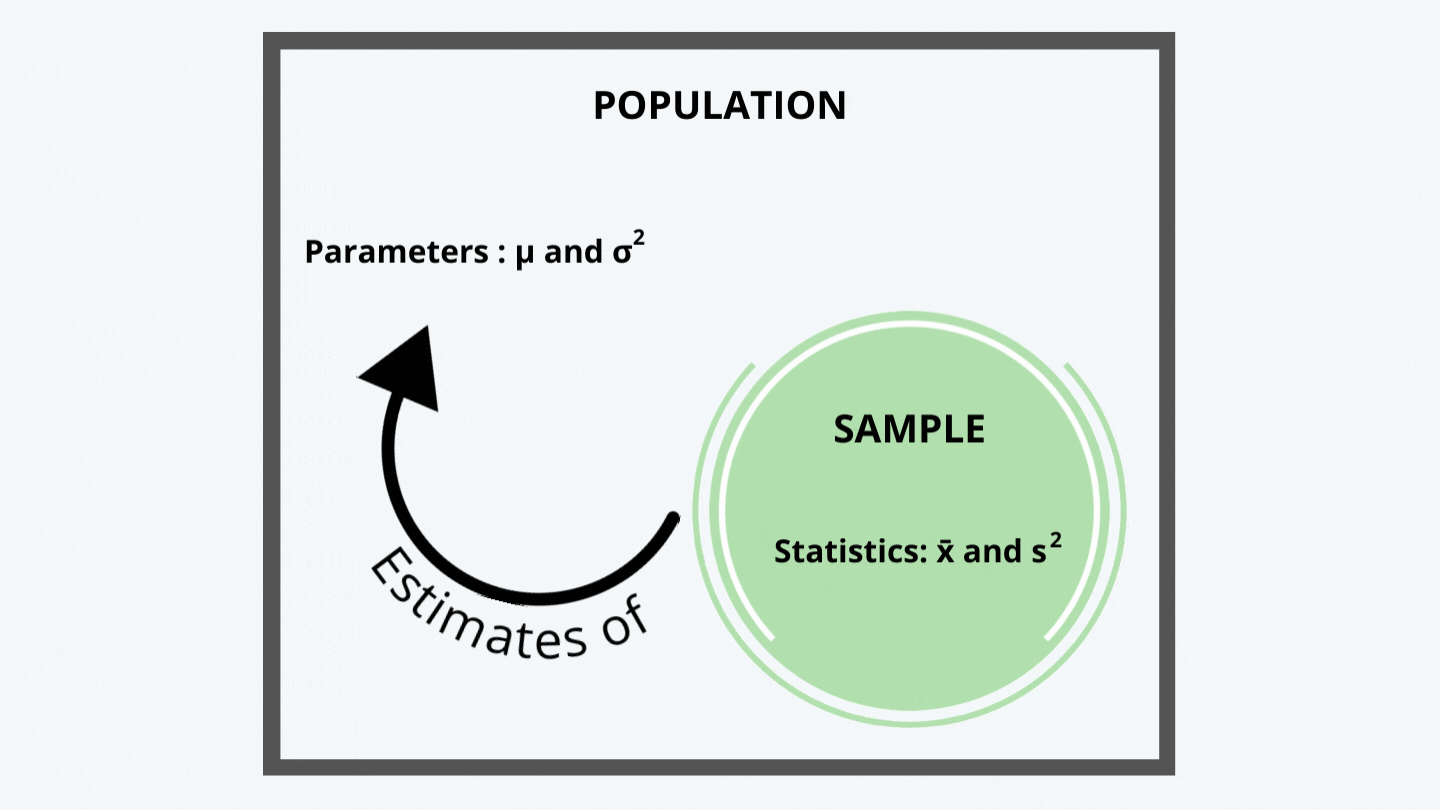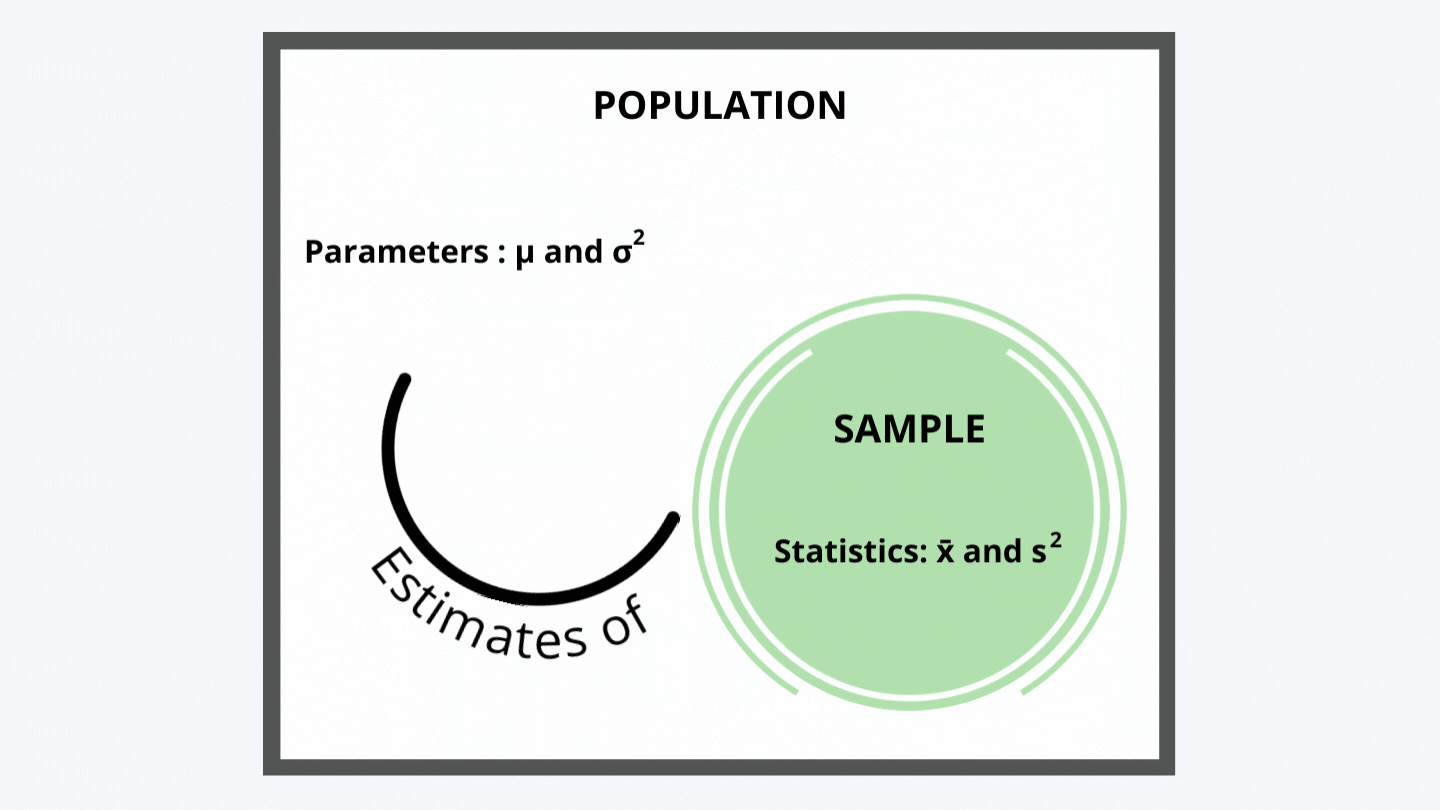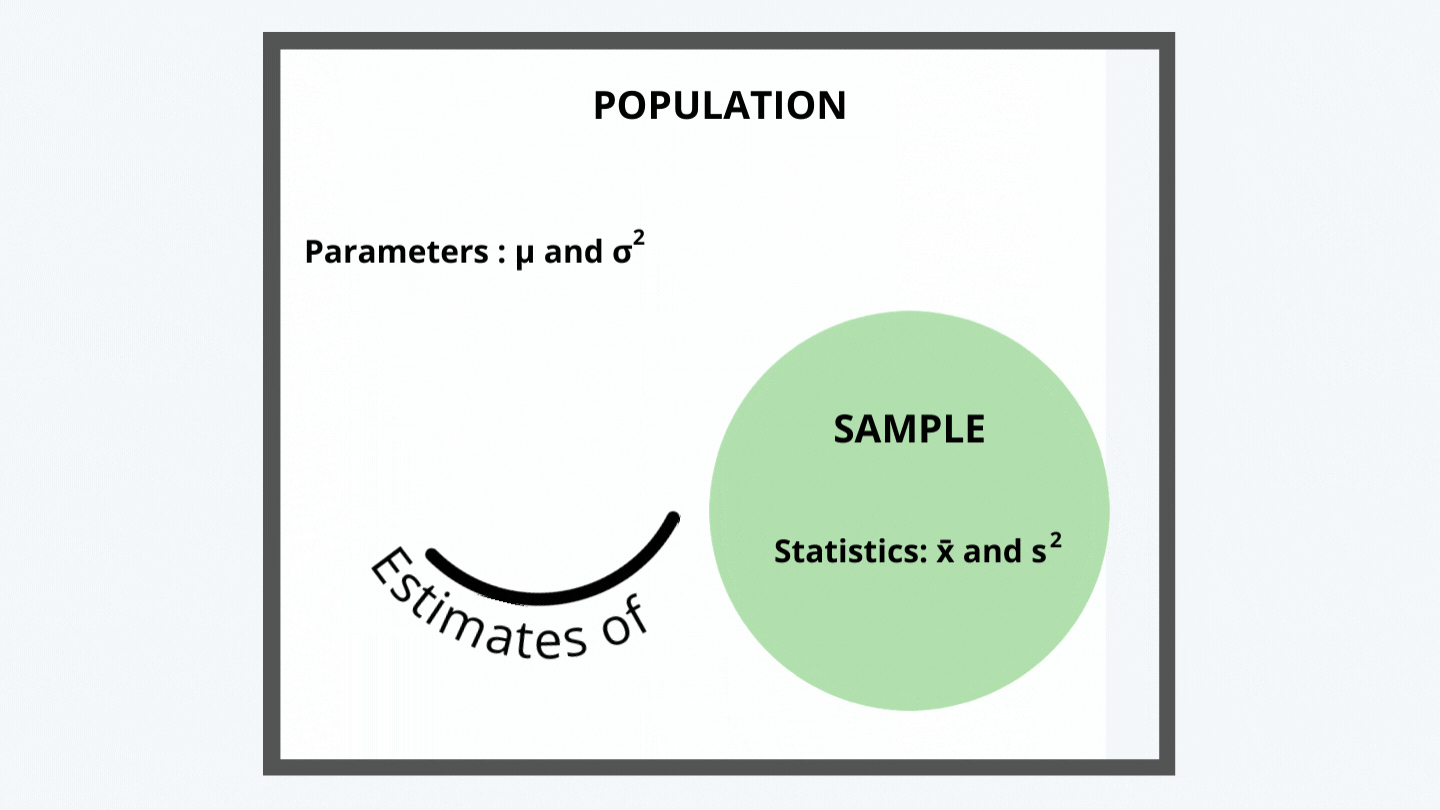
a. All the data concerning information is called the population of the data.
b. The parameters are the measurable characteristics of the entire population data, such as its mean and variance.
The population mean and variance is generally denoted by the sign µ and σ2.
c. A parameter is a quantity used to describe a population, and a statistic is a quantity computed from a sample and is used to estimate a population parameter and describe the sample.
d. The sample statistics are used to estimate the parameters because it is not always feasible and possible to examine the entire population. It could be just too expensive to do the same.
We, thus, calculate the sample mean and sample variance, generally denoted by the symbols x̄ and s2.
e. Consider the following figure:
f. In order for a calculated statistic to convey information about the related population parameter, the sample should be chosen wisely to reflect the parameter’s characteristics. There are certain conditions that must be met; those conditions are generally satisfied if the sample used to calculate the statistics is random.
2. Random Samples
a. A simple random sample is a subset of the population drawn in such a way that each element of the population has an equal probability of being chosen.
b. The simple random samples can be chosen using one of many techniques, such as:
i. Using a random number generator, which generates certain numbers and those variables that lie on that number in the sequence get selected as a sample.
ii. Using systematic sampling techniques, such as selecting every kth element in the sequence of variables.
c. There are many different samples possible in the population and each of such sample’s mean and variance may not equal the other.
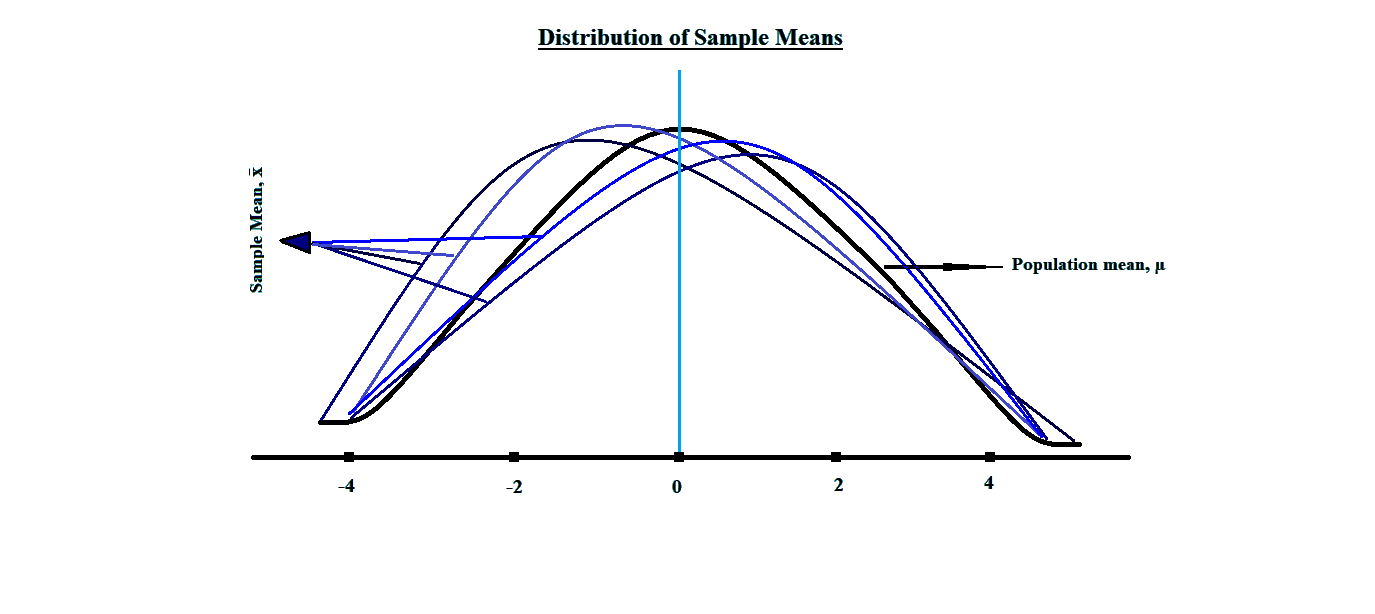
So that if we take a sample at random can calculate its mean and variance as and may not equal the other x̄2 and s22. Such that,
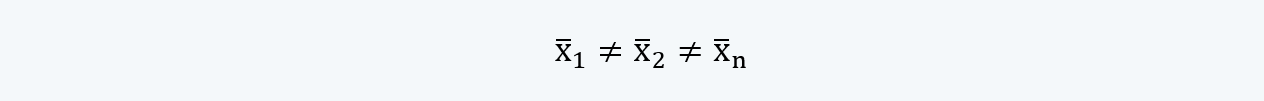
And, usually, none of the sample’s mean equals the population’s mean and variance. The means of all the samples in a data are usually distributed normally; and if we want to calculate the mean of the population using these sample’s mean, we would calculate the mean of the sample means, which is equal to the population mean. That is,
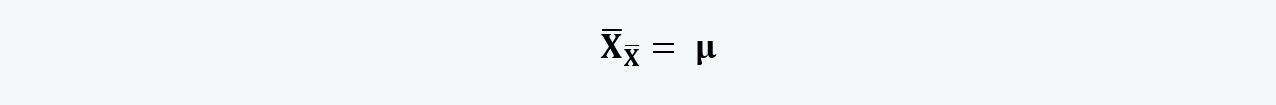
d. Since the population mean is mostly not equal to the sample’s mean; therefore, there is always a difference between these two means. This difference between the population mean and the sample mean is called the sampling error. That is:

e. The difference between the observed value of a statistic and the value of the parameter is known as the sampling error.
3. Stratified Random Sampling
a. In a large population, we may have subpopulations, known as strata, for each of which the analysts want to ensure inclusion in a representative way in the sample.
To do so, we can use stratified sampling, wherein we draw simple random samples from each strata and then combine those samples to form the overall sample on which we perform our analysis.

b. The main steps involved in stratified random sampling are:
i. Step 1: The population is first divided into sub-populations called the strata.
ii. Step 2: Simple random samples are drawn from each strata in proportion to their size.
c. Each of the strata, so divided, should be:
i. Mutually exclusive, and
ii. Collectively exhaustive.
d. By using this technique, we get a sample that looks more like the population with more precise estimates of the sample mean and the variances (i.e. x̄ and s2). This is mainly because; the representativeness reduces the sampling error.