LOS G requires us to:
calculate and interpret 1) a range and a mean absolute deviation and 2) the
variance and standard deviation of a population and of a sample.
Dispersion is nothing but the variability around the central tendencies. There are different measures of dispersions, they are:
1. Range
The range is the difference between the maximum and minimum values in data.
|
Range = Max – Min |
The range gives a basic idea about the extent to which the limits within which the variation is possible. The shortcoming of using range as a measure of dispersion is that the extreme values or outliers may distort the range.
2. Mean Absolute Deviation
Mean absolute deviation (MAD) is the average distance between each data value and mean. However, while calculating the mean, the negative deviations are converted to the positive ones by modifying them or taking their absolute values.
The formula for calculating MAD is:
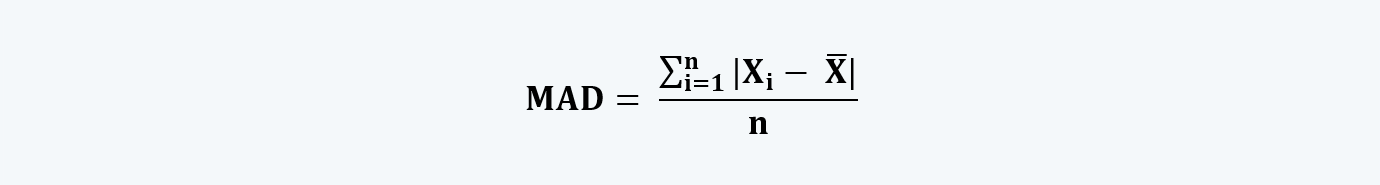
3. Variance and Standard Deviation
a. Variance is the squared deviation of the random variables in a data set from its mean. The variance of the parameters, i.e. the population data can be calculated using the following formula:
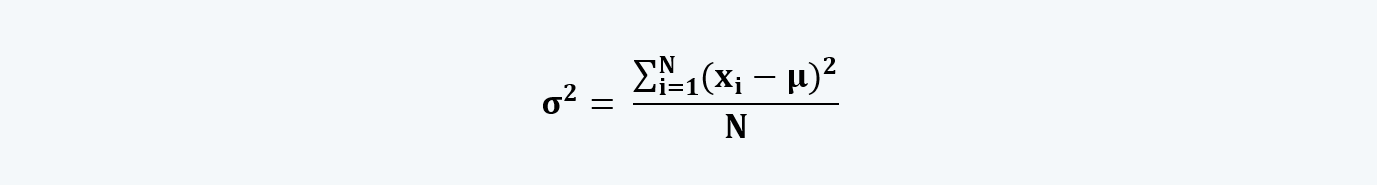
b. However, if we take the sample from the population, considering it as a reflection of the population at large, then the formula for calculating the variance is:
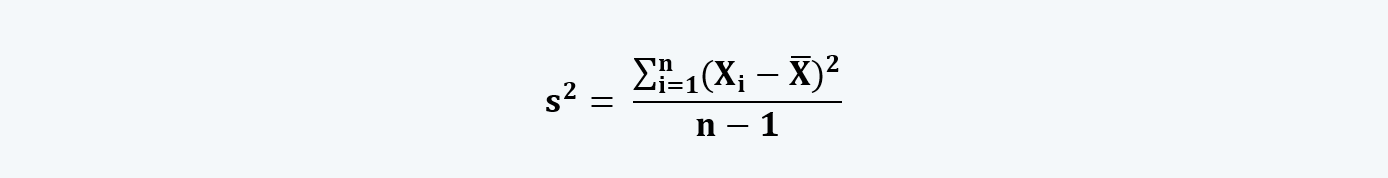
c. While calculating the sample variance, we use ‘n-1’ as the number instead of ‘N’. ‘n-1’ represents the degree of freedom while using the sample data instead of population. It represents the minimum number of independent ways in which a system can vary. We know that Σ (Xi – x̅) = 0, therefore, if we know the values of (n-1) observations, we can also calculate the last. Thus, this value is not independent.
Example:
Taking the data given in the previous example of the return on equity stock, we can calculate the variance and the standard deviation as follows:
|
Year |
Return on Equity |
Variance |
|
|
1 |
-2.00% |
=(-2-3.80)2 |
0.34% |
|
2 |
8.00% |
=(8-3.80)2 |
0.18% |
|
3 |
27.00% |
=(27-3.80)2 |
5.38% |
|
4 |
-9.00% |
=(-9-3.80)2 |
1.64% |
|
5 |
-5.00% |
=(-5-3.80)2 |
0.77% |
|
Average: |
3.80% |
Variance: |
2.08% |
d. The standard deviation, on the other hand, is the square root of the variance. It measures the dispersion around the arithmetic mean.
Thus, the standard deviation of the population data is:
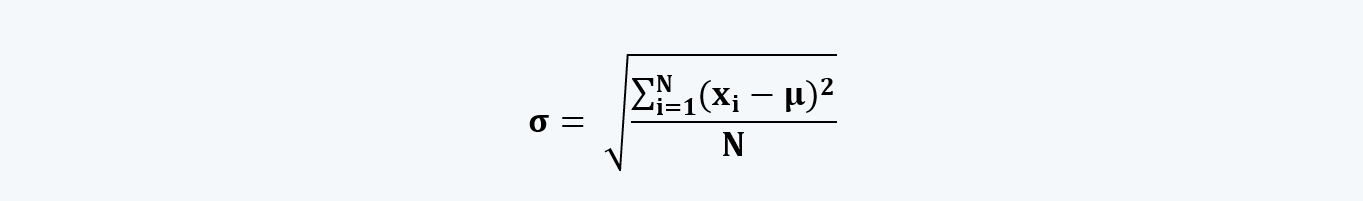
And the standard deviation of a sample data is:
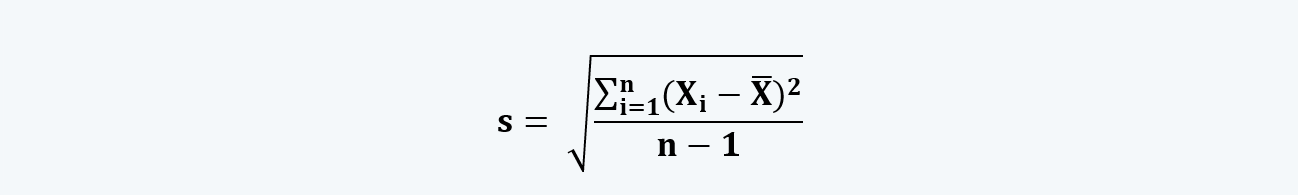
e. However, if we are given geometric mean instead of the arithmetic mean, we can calculate the dispersion around it using the following formula:
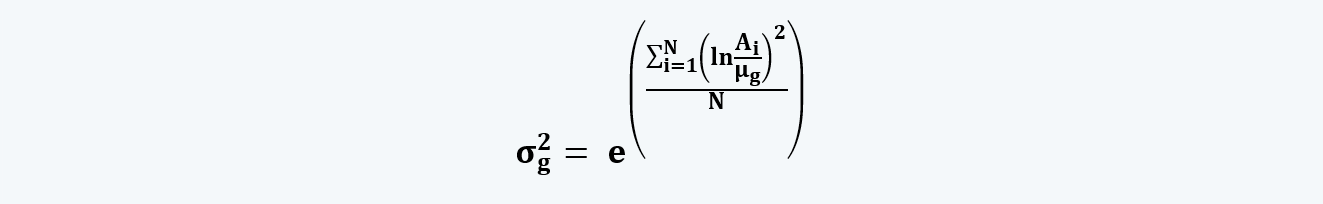
4. Semi- Variance
a. Semi-variance measures the dispersion of all the observations that are less than the mean.
b. It can be calculated using the following steps:
i. Find x̅
ii. Select all the observations that fall below x̅
iii. Calculate the semi-variance using the following formula:
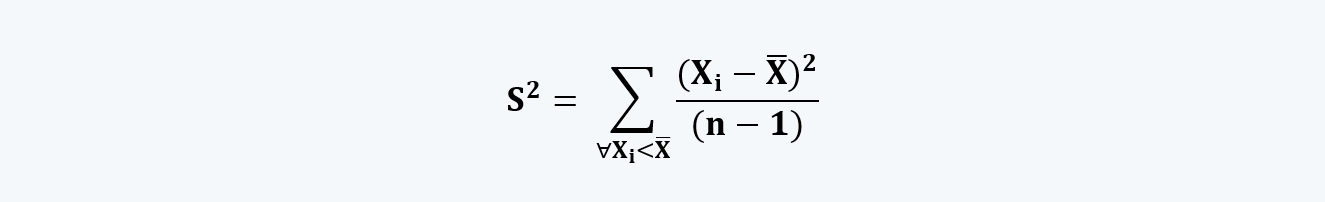 |
c. The ‘n’ that we use in the calculation of semi-variance reflects the full data set and not just the observations that fall below the mean.
5. Semi-Deviation
Semi-deviation is the square root of the semi-variance.