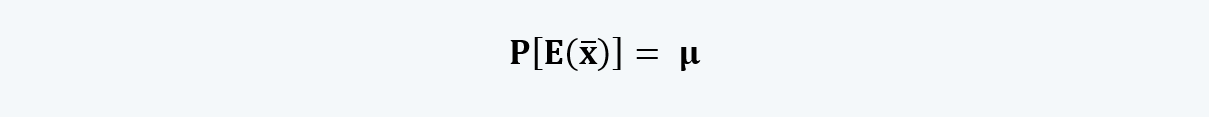LOS G requires us to:
identify and describe desirable properties of an estimator
a. When we take samples from the population, we calculate its mean and the variance. These are the values at a single point, and thus the point estimates. And, the formulas used in the calculation of these estimates are the estimators.
b. Estimators are the generalized mathematical expressions for the calculation of sample statistics, and an estimate is a specific outcome of one estimate.
c. Estimates take on a single numerical value and are, therefore, referred to as point estimates. It is a fixed number specific to that sample. It has no sampling distribution.
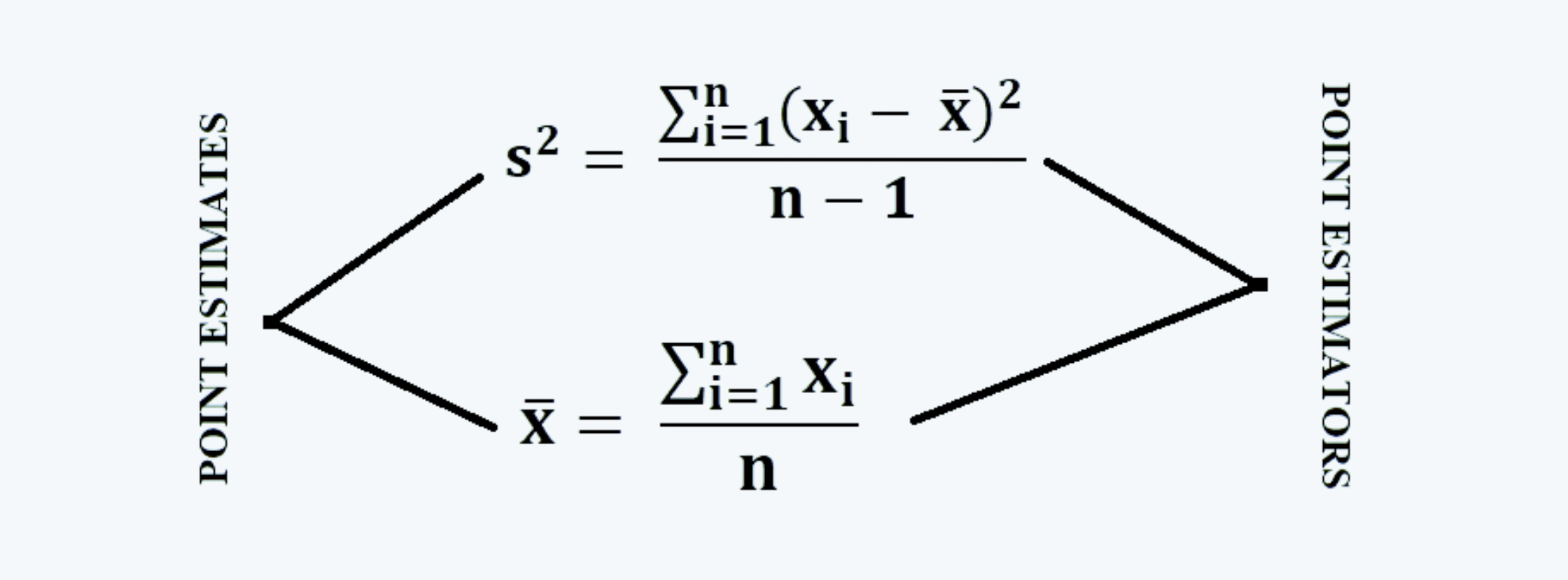
d. The point estimators should have certain desirable properties, they are:
i. Unbiased: An estimator is considered unbiased when the estimated expected value calculated using the estimator is equal to the value of the parameter being estimated.
For example, the value of the sample mean and variance must equal the value of the mean and the variance of the population. That is,
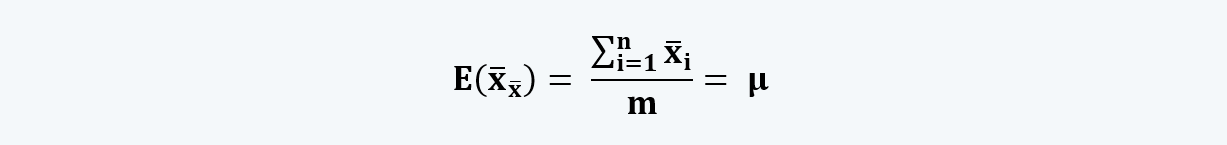
Where n is the sample size and m is the number of samples.
And,
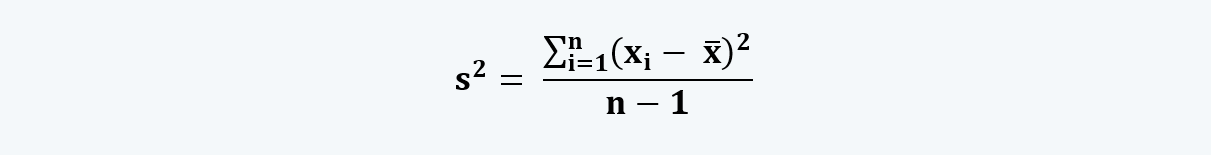
Note, that here we use n-1 instead of n because, if we had used n as the denominator instead, it would have produced a consistently smaller variance, hence creating biasedness.
ii. Efficiency: An estimator is said to be efficient when no other estimator has a smaller variance.
Consider the following figure, for example:
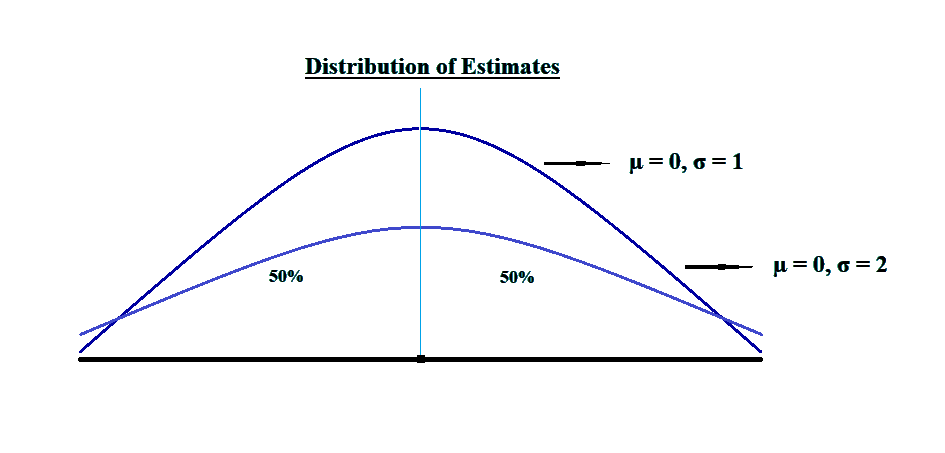
In the above figure, the distribution with a higher graph has a lower standard deviation, therefore, it makes a better estimate.
iii. Consistency: An estimator is considered more consistent when the probability of obtaining estimates close to the value of the population parameter increases as the sample size increases. Consistency is asymptotic in nature, thereby requiring a large number of observations.
Thus, for an estimator to be consistent,